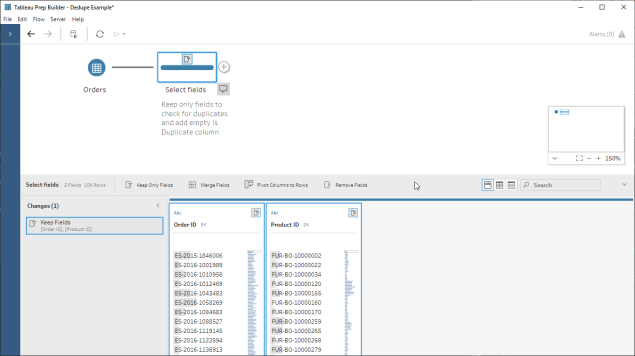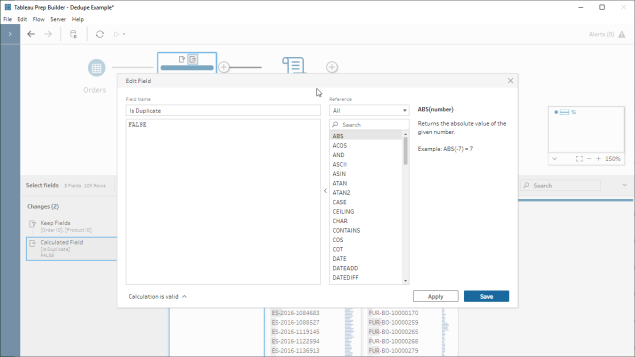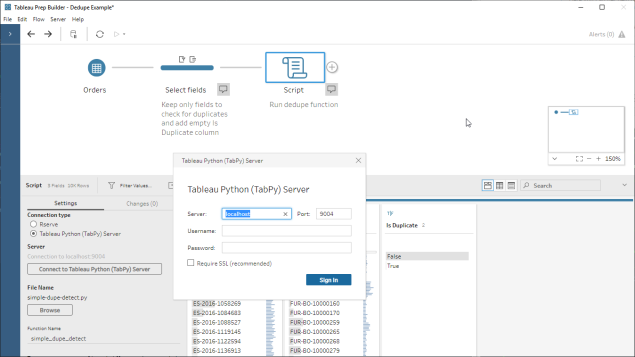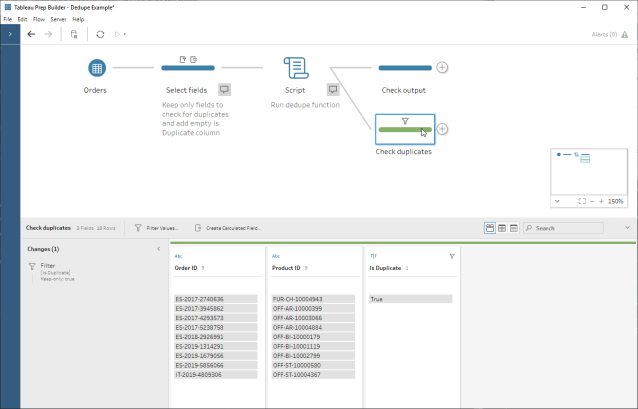
As of version 2020.1.3, Tableau Prep now has the capability to create analytic calculations and {FIXED} LOD calcs – something many I’ve been hoping for ever since I first saw Prep back in 2018! They help us to answer questions that previously needed table calcs, hiding rows, and tricks in Tableau Desktop, or just simply weren’t possible and needed some data prep pre-Tableau.
A caveat that comes with building these fields using these calcs in Tableau Prep is that they’re not dynamic – they won’t respond to filters, for example – so you may find yourself coming back to Prep to create a new fields for each specific question. Nevertheless, these calcs make tackling the cases below much easier than before.
Being in Coronavirus lockdown has given me time to write up my favourite uses (not in order of importance) for these new calcs; this Prep flow has a worked example for each use case.
1. Adding a simple row identifier to your data:
More often that any of us would like, we come across (or get given) datasets that have no unique identifier, or each row’s uniqueness is a combination of different columns (and we’re left to work out which ones they are for ourselves). Worst of all is where there’s nothing to identify that each row is a distinct ‘thing’, save for the fact that it’s a different row!
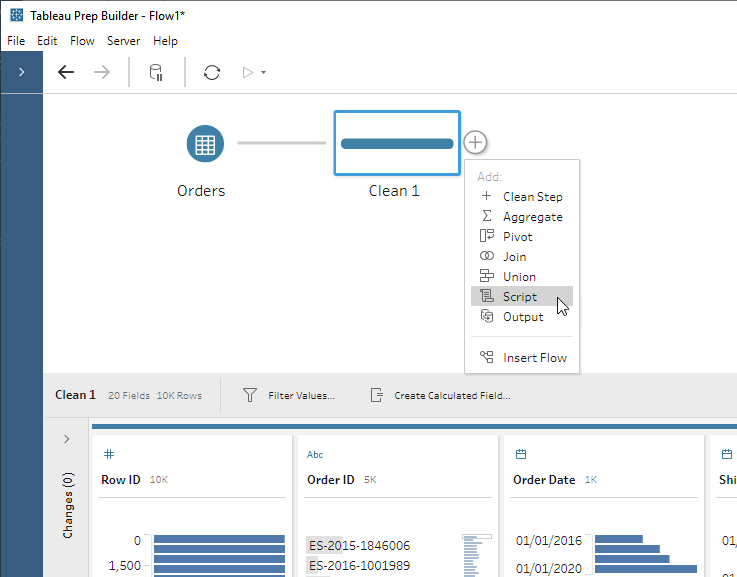
To create a row id, click the Create Calculated Field… icon and use the calculation:
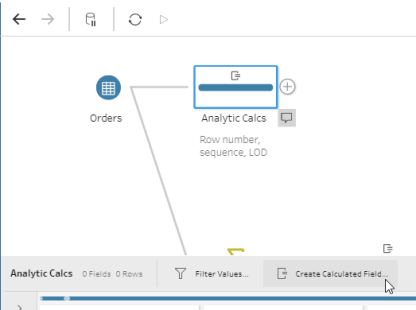
{ ORDERBY [Some Field]: ROW_NUMBER()}
Note: There’s a catch to be aware of with the ROW_NUMBER() function, in that you have to order by a field (it’s not possible to retain the incoming row order). What this means is that as it stands, it’s not possible to create a calc that records the original sort order (yet).
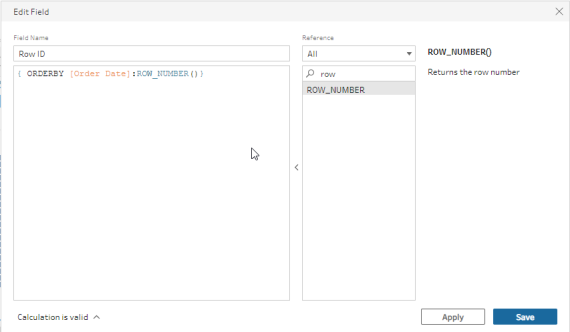
Now we can use our Row ID as a dimension in Tableau and display individual rows where we need to.
2. What did the customer buy in their 3rd order?
Ordering sequential events:
I worked with a customer running a subscription business who wanted to know all about customers’ third order, since their first two came under an introductory offer. Answering questions about a customer’s nth order can be fiddly to answer using Desktop/Web Edit alone and involve table calculations to get the nth, hiding rows, and difficulties doing deeper analysis on those orders. The RANK() function can make this simpler by ranking a customer’s orders by date (or any other field for that matter). If we write our calculation
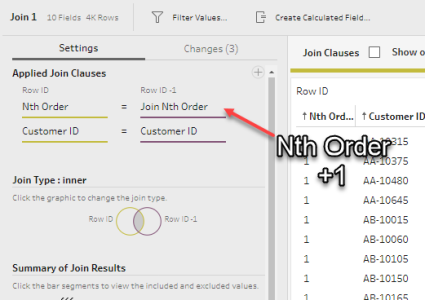
{ PARTITION [Customer ID]: { ORDERBY [Order Date]: RANK()}}
then we get an incrementing number for each order date – telling us the nth order for each customer:
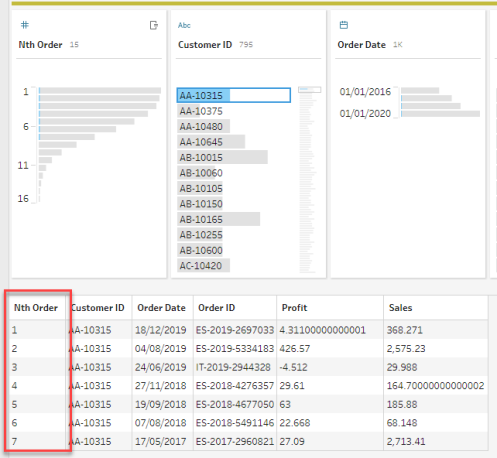
Now if we want to analyse how each customer’s third order (if they had one) we no longer need table calcs, we can just filter on our Nth order column.
3. What’s the average interval between a customer’s orders? Can we analyse those ‘high frequency’ customers?
Making comparisons across rows:
Segmenting your customers by the frequency at which they normally ‘do stuff’ (like placing a new order) means that you can track and treat them differently, and possibly intervene when they haven’t ordered for a while. Whilst calculating the time difference between orders is easy with a table calc, it’s tricky is to go further and analyse those ‘frequent orderers’ since table calcs require you to have all data in your view.
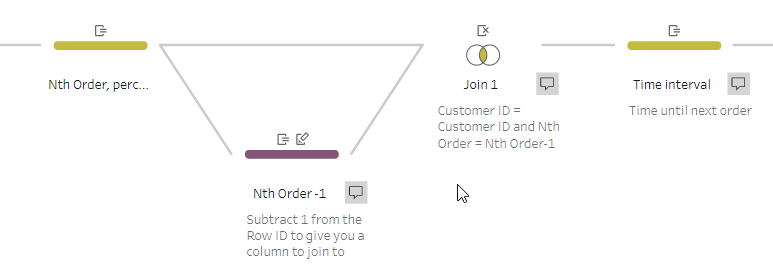
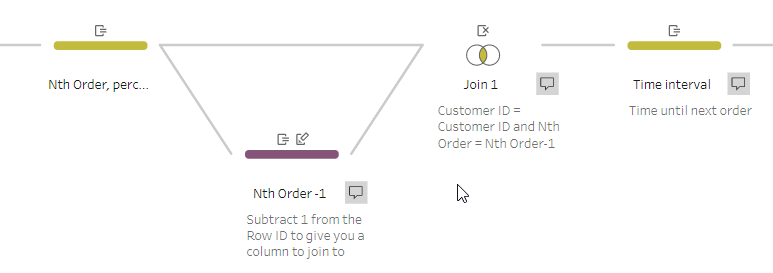
To calculate the time difference between orders, we need to look at the row below each one and compare the dates – effectively a lookup function. This capability isn’t immediately apparent since there isn’t a lookup function in Prep as such; however (and this is sometimes how I do it in SQL anyway) we can take our Nth Order field above and then join the data to itself like so (written in SQL style, nowhere in Prep will you have to type anything like this):
[Customer ID] = [Customer ID] AND [Nth Order] = [Nth Order]-1
Order 1 from the left side will be paired with Order 2 from the right for each customer, so now the columns from your right-hand side represent the next order in sequence. The linked Prep flow will illustrate this better than I can articulate it!
Once we have the time interval, we can easily group our customers into buckets and begin our analysis. More on this below…
4. Pre-computing LOD calcs for performance (at the expense of flexibility)
Now that we’ve got our time interval, can we group our customers into buckets based on their average order frequency? What we want is the average order interval at a customer level.
LOD calcs in Desktop / Web Edit are perfect for this, but with lots of them on lots of data, you can start running into performance issues. You might choose to pre-compute your calculations in Tableau Desktop to alleviate this – however, since LOD calcs are dynamic based on your view, they can’t be pre-computed. The new LOD calc offers a way of pre-computing this into your data source and saving the performance hit of LODs.
This has actually already been possible in Prep using a combination of an aggregation followed by a self-join, but was a time-consuming workaround and ran into problems if you didn’t have a nice unique id for the thing you were aggregating.
Warning – given the caveat about dynamic-ness (dynamism? dynamicity?) above, I would only recommend this in cases where performance is a significant issue and you have already decided what views you need, since your LOD calc will no longer take into account any filters. As such I’d only recommend this part of a performance fix on a finalised and relatively fixed dashboard view!
LOD calculation syntax is exactly the same in Prep as in Desktop/Web Edit:
{ FIXED [Customer ID]:AVG([Time until next order])}
Now that we have this, it’s easy to bucket up our customers in Tableau with some calculations and save re-computing the LOD.
5. What percentile does each order sit in? Can I filter out outliers? Calculating percentiles:
Just as in Desktop/Web Edit, the RANK_PERCENTILE() calc calculates what percentile each row is based on a measure, within a certain set of rows – for example, which orders are the top 5% in terms of total profit made in a given year?
Like the examples above, this is something that can be done with a table calc but it’s difficult to analyse further. Happily, Prep makes this easier and the syntax is just like our RANK() above:
{ PARTITION [Order Year]: { ORDERBY [Profit]: RANK_PERCENTILE()}}
Note that you can’t do calculations inline – and if you try you’ll get this error message: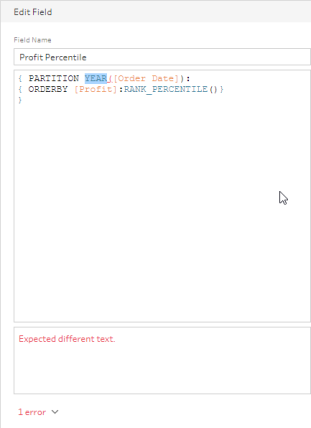
Now we have the percentile that is fixed in our data, so it’s easy to filter and aggregate without disrupting the percentile calculation.
For the moment, these are the top use cases that have come to my mind but I’m sure there are more out there – please let me know of any in the comments below or tweet me @honytoad !