With the release of the Script step in Tableau Prep 2019.3, it’s possible to integrate Python with Tableau Prep to fetch data from web APIs, use Google’s Geocoding API to fetch postcodes, or deploy predictive models on your data, to give just a few examples. Tableau can already integrate with Python as a table calc on aggregated data, but Prep integration allows us to run Python functions at row level which is more suitable for use cases like sentiment analysis, where it’s most helpful to score text row-by-row before aggregating in a viz. Here’s a step-by-step guide!
All the files for this blog post can be downloaded from here.
Getting started
The rest of this post assumes that you have already installed python on your machine. If you haven’t, the Python downloads page here but beware that choosing which version(s) to install can be frankly confusing (not to mention whether to use the Anaconda distribution or not). This post offers a decent summary of where to start and the differences between Python 2.7 and 3.x (even for mac users, although macs come with Python 2.7 installed), as does this article from Real Python.
The Script step in Prep allows you to connect to a Python or R service running on a machine (either the same computer that’s running Prep or a separate server) and pass the data in Prep to it as a dataframe; for R this would be a native dataframe and for Python this means a pandas dataframe.
Integrating Tableau with Python requires TabPy, a framework that allows Tableau to execute Python code and pass data to it.
Update, 25th March 2020: As of Tableau 2020.1, TabPy is now fully supported by Tableau and has an easier installation process, as well as some pre-built statistical functions for easy use in Tableau (or anywhere else!) and other enhancements.
- Install TabPy using pip – simply a case of typing pip install tabpy in your command line
- Develop your script(s); I personally use Spyder (which comes with Anaconda) but there are loads of alternatives including PyCharm, Jupyter, and SublimeText
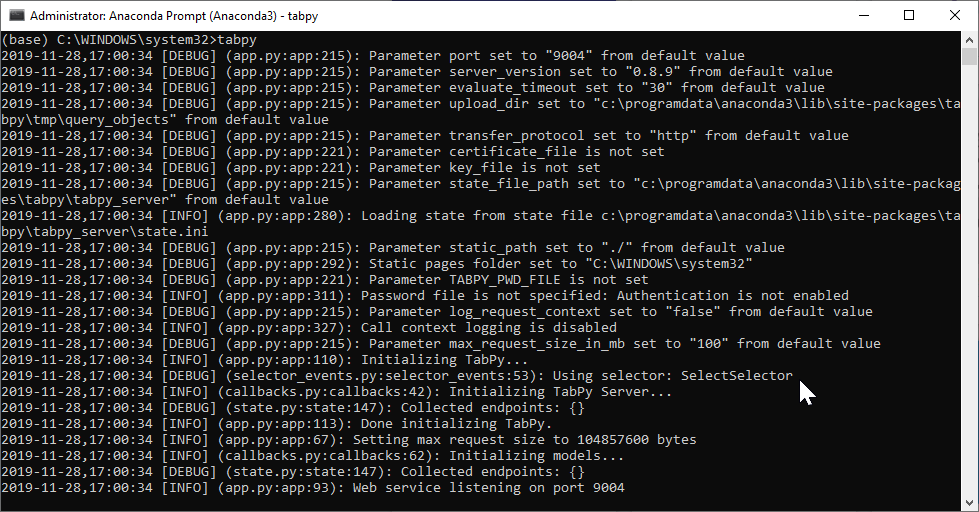
- Start TabPy. How exactly you do this depends on your installation, I do this through Anaconda Prompt using the tabpy command. By default TabPy runs on port 9004; here’s how the console looks when it’s running:
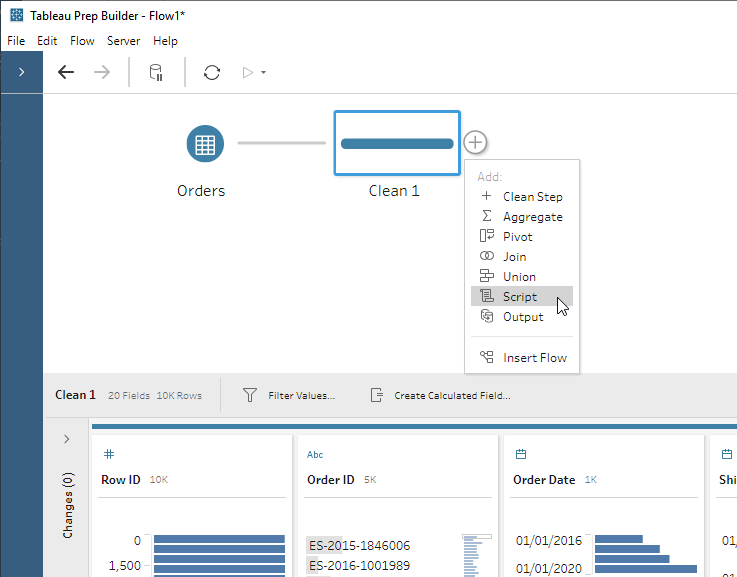
- Insert one or many Script steps into your flow, point them at your pre-written script file, and tell them which function to use.
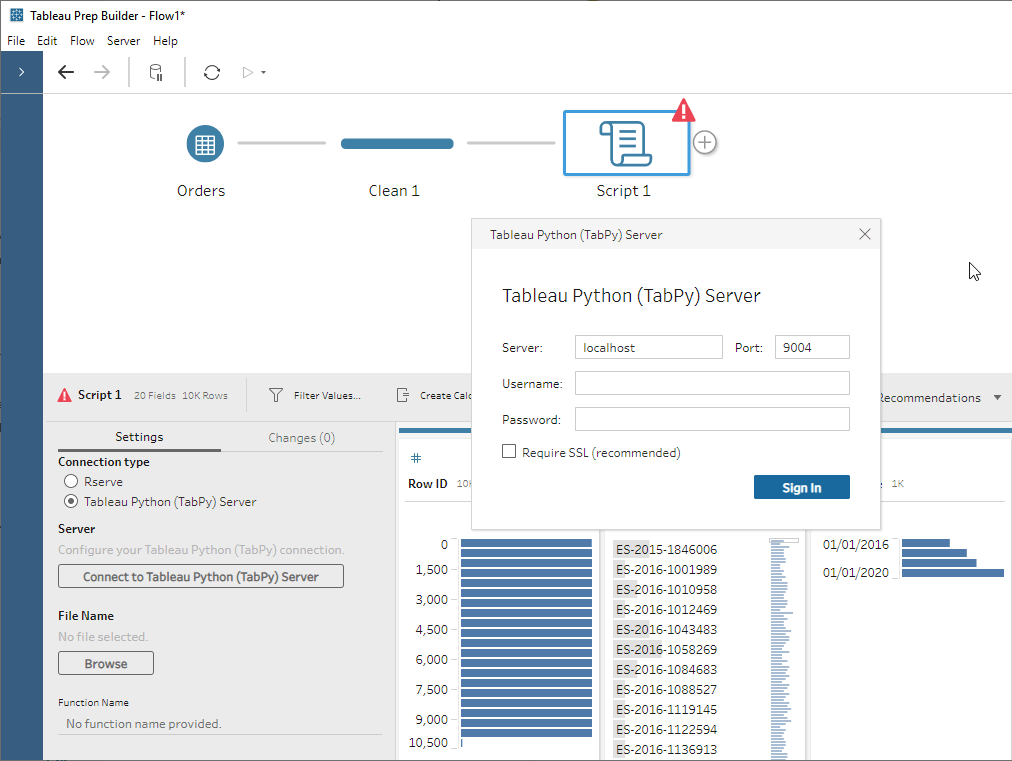
- Run the flow. You can run it manually, use Prep Conductor in Tableau Server with the data management add-on, or from the command line; as of now Tableau Online doesn’t support external service connections.
The script
So what does your python script need to contain?
- One or more functions to be executed by Prep that accept a dataframe as their only input and return a result, which Prep will take as the script step’s output. Note that in some cases you might be using a script purely to fetch external data as an input to Prep, in which case you can simply send it a dummy value.
- As an optional requirement, if the number or data type of columns in your function’s output is different to the input from Prep, then you will need to create a function called get_output_schema to tell Prep what schema to expect from the script. More on this below.
Note that the first thing that Prep does is run the entire script. This means that any importing of modules and supporting functions will be run, but this also means that any code that you might have used for testing will get run too, so comment out/remove any non-essential code. Be careful if your comments contain any file paths with escape characters in, even if commented out they can sometimes throw an error (at least in version 2019.3.1).
Worked example #1 – detecting duplicates across a set of columns
In this example we want to see if there are any duplicate rows in our EU Superstore. Python’s pandas library has a really good function for doing this called duplicated. As a product consultant I often get customer datasets without much explanation to them, so checking for duplicates (in)validates my assumptions about the uniqueness of each row.
Step 1: Create the function we are going to call from Prep
The dedupe function itself is pretty simple, just adding a column to the dataframe as the result of the duplicated function:
import pandas
def simple_dupe_detect(df):
print('\nChecking if input data contains any duplicates across all columns...')
df['Is Duplicate'] = df.duplicated(keep=False)
print('Number of rows: ',len(df))
print(len(df[df['Is Duplicate'] == True]),'duplicates found')
return(df)
There are a few things to note:
- The function itself can only take one argument, the dataframe from Prep.
- Printing things to the console means you can look at your open TabPy console window and check what’s happening to help you debug (I never get my scripts right first time!).
- Prep seems to run the script quite frequently as you navigate around the Prep tools for it to refresh the data – watch out for hitting any API or data limits as the number of rows queried can add up.
- Any changes (filters, calculated fields) you make in the script step will happen on the script output, not the input!
Step 2. Define your output schema (optional)
Now we need to create a function called get_output_schema.
The get_output_schema() function needs to return a pandas dataframe with the columns, each with its defined Prep datatype. There are 6 Prep datatypes:
| Function in Python |
Resulting data type |
| prep_string () |
String |
| prep_decimal () |
Decimal |
| prep_int () |
Integer |
| prep_bool () |
Boolean |
| prep_date () |
Date |
| prep_datetime () |
DateTime |
Here’s an example:
def get_output_schema():
return pandas.DataFrame({
'Order ID' : prep_string(),
'Product ID' : prep_string(),
'Order Date' : prep_date(),
'Quantity' : prep_int(),
'Sales' : prep_decimal(),
'Is Duplicate': prep_bool()
})
An important consequence of having to predefine the output schema means that you can only have one output schema per script. This makes it more complex to write a generic script that can be inserted into any workflow. For our deduping example this means I have to decide which columns I want to check for duplicates in advance, then tailor the script to those columns.
Ideally we would find a way for our script to examine the output from our chosen function and dynamically generate the output schema. However, get_output_schema() seems to be the very first thing in the script that Prep runs (i.e. before your chosen function can produce any output) so I haven’t yet worked out a way to do this, if it’s at all possible.
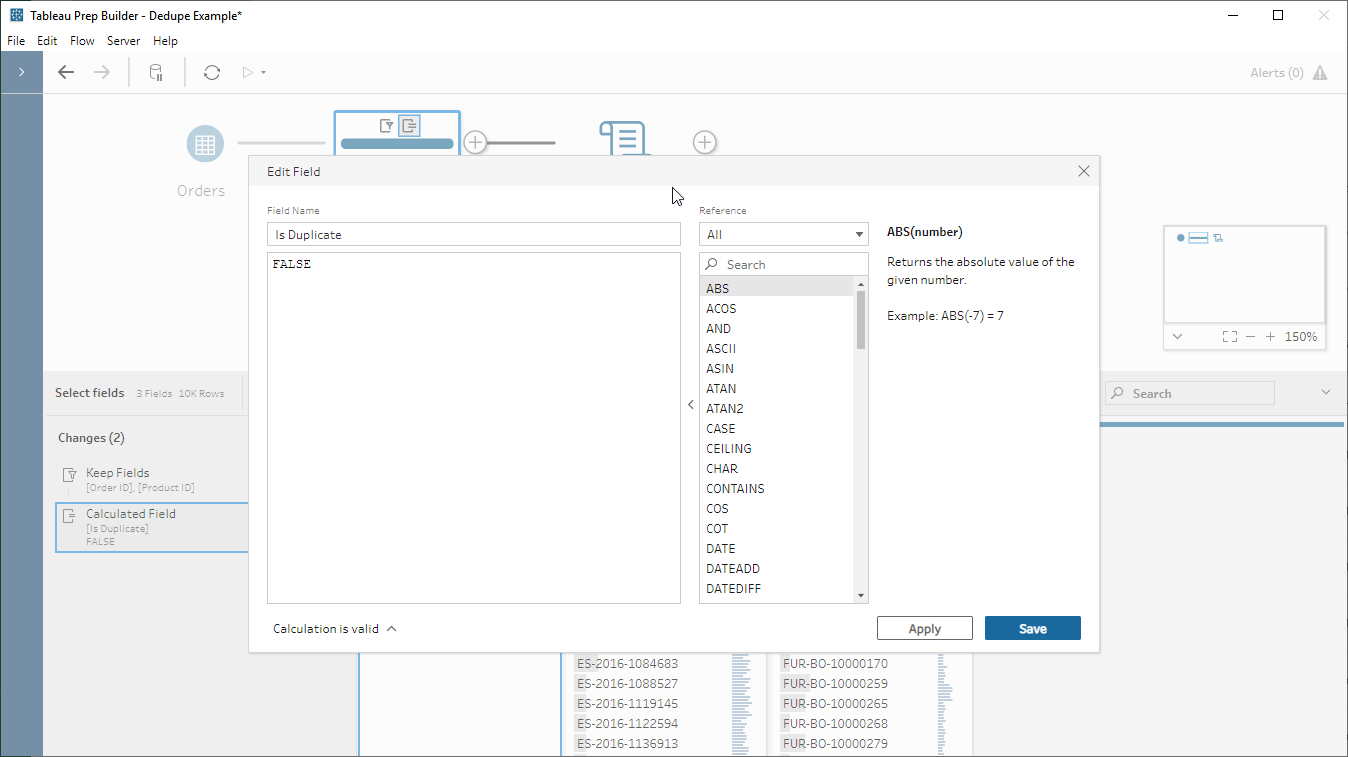
However – there is a simple if somewhat cheeky workaround – simply add a column called ‘Is Duplicate’ in Prep, assign it a dummy value with the correct datatype, and pass that into the script. Now my data out of the script will always have the same schema as the data going in – which means I don’t need to write get_output_schema and I have a generic deduping script that I can use in any flow at any point. Easy!
- Keep only the fields we want to check for duplicates:
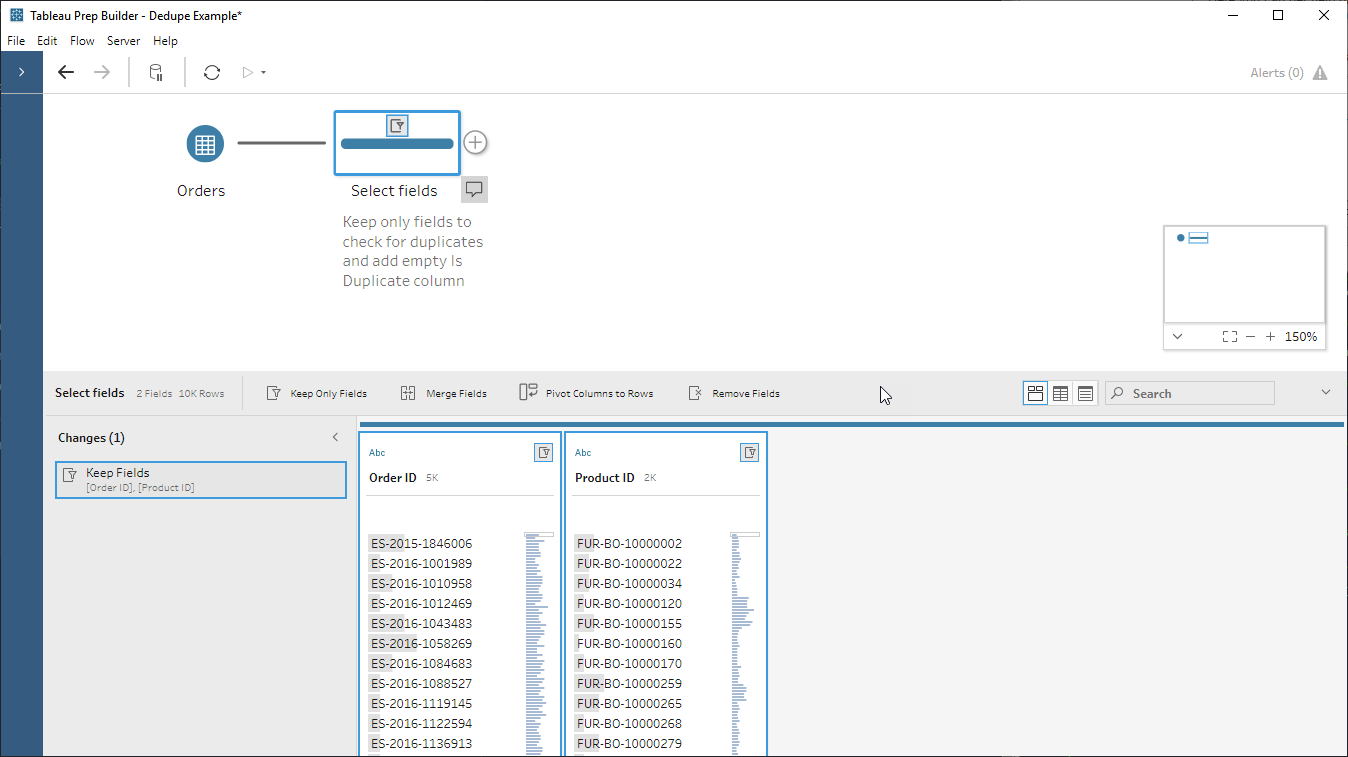
- Create our Is Duplicate column with a dummy value, here I just put FALSE to make sure it’s a boolean:
- Insert and configure our script step:
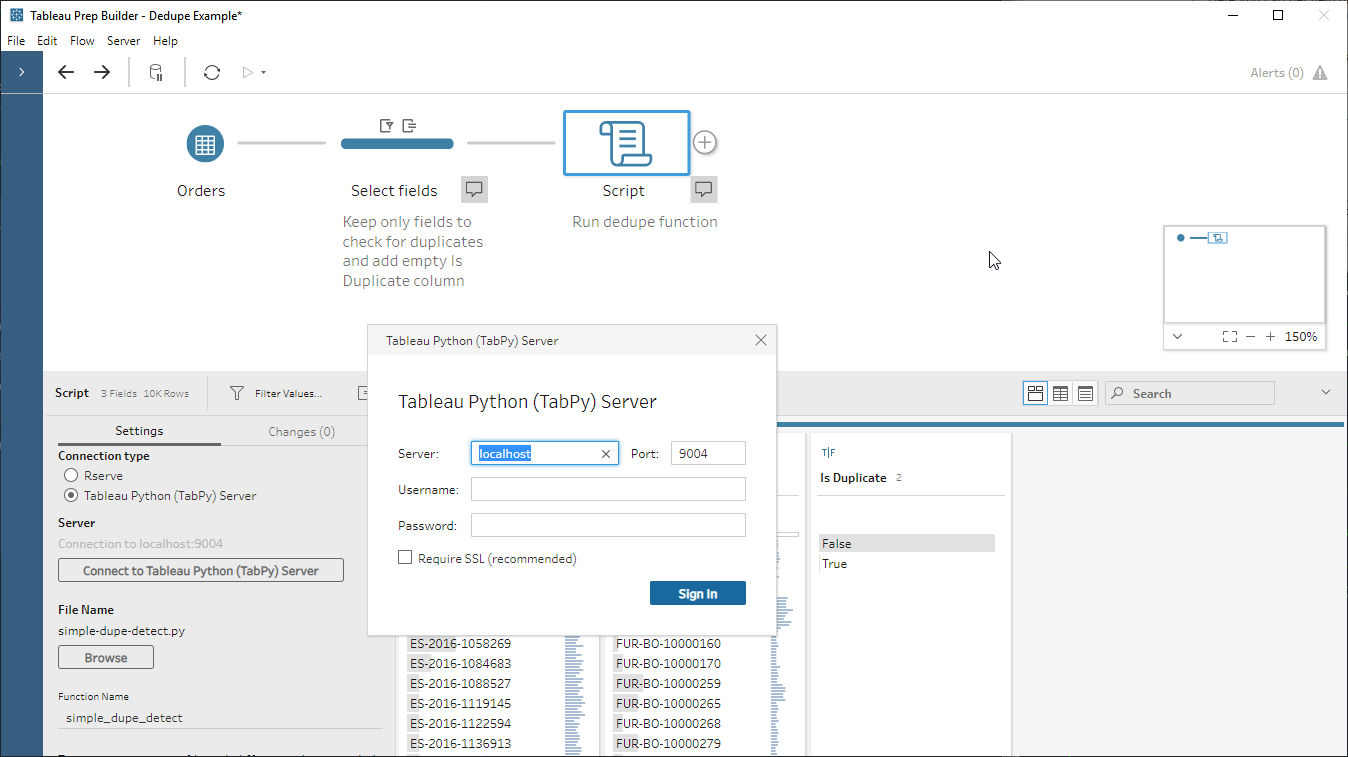
- Taking a look at our duplicated records, it turns out that there can be more than one row for the same product in the same EU Superstore order – who knew?
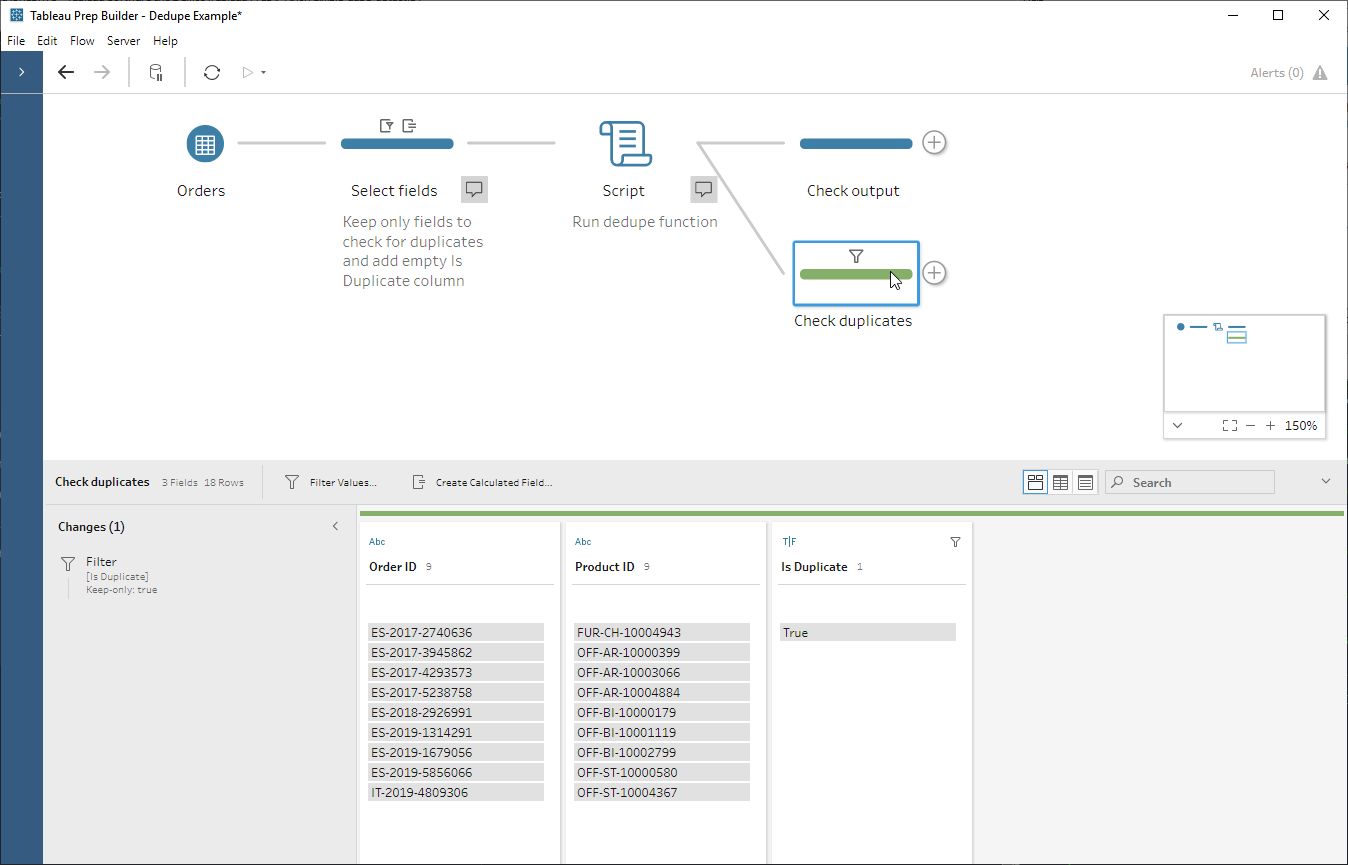
And now we have the end-to-end flow: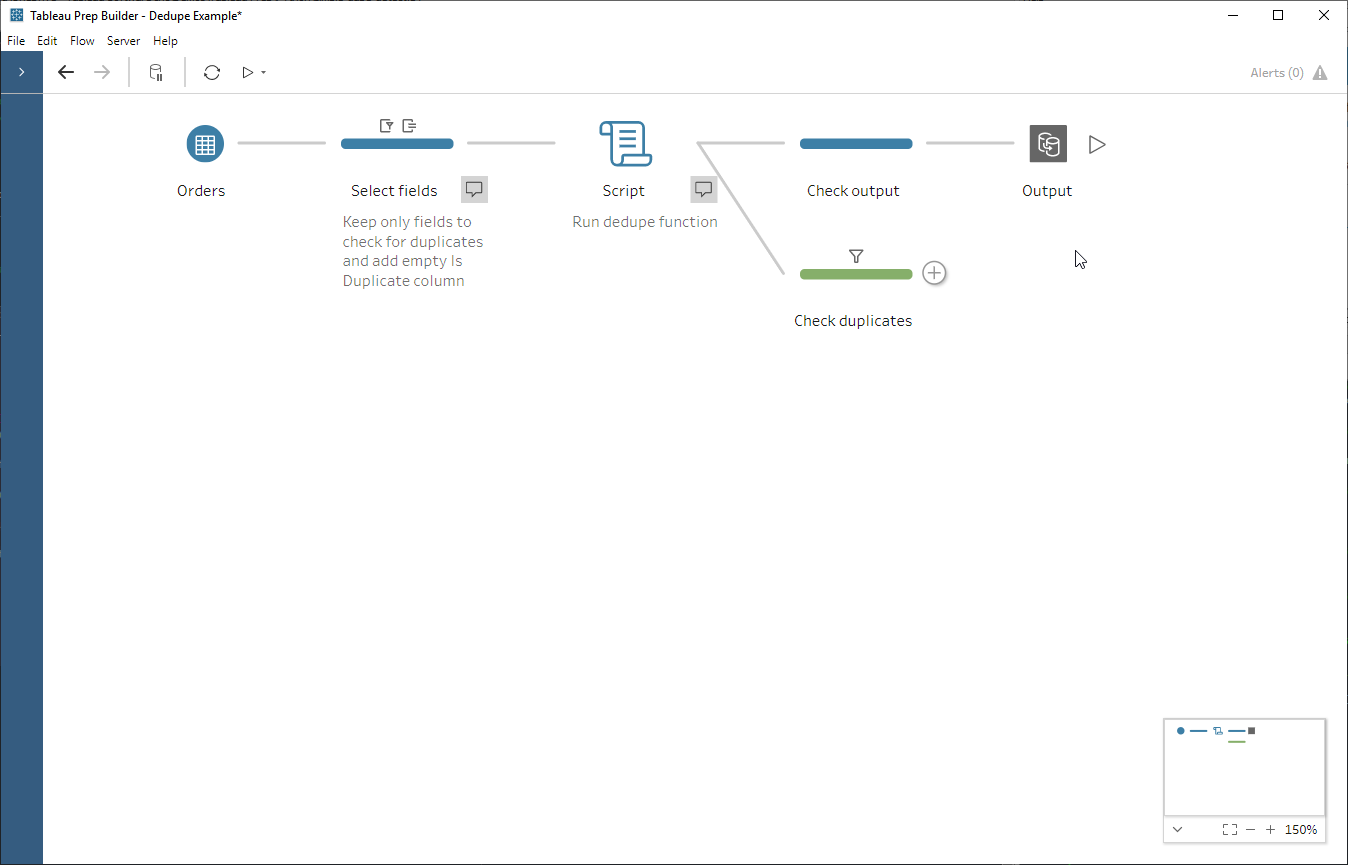
Worked example #2 – Fetch data from a REST API and bring it into Prep
The script step also allows us to bring in data from outside of Prep, for example from an API, or semi-structured data source like XML that needs some flattening. You can’t use it as an input step (i.e. it always needs an input itself) but you can circumvent this by simply having a dummy file as input. In this super simplified example we are going to fetch data from the Punk API (thanks very much to @samjbmason) to get information about Brewdog’s beers.
This time our script will fetch the beers JSON data, flatten it, and pass it to Prep. I’d like to break out hops from the beers data as a separate table so I’ll need a different get_output_schema function – and therefore a different script – to do this. Again, the code itself is simple:
import requests as req
import pandas as pd
# function to fetch data directly from the punk API
def get_punk_from_api(df):
payload = req.get('https://api.punkapi.com/v2/beers?per_page=80', verify = False)
data = pd.io.json.json_normalize(payload.json(), max_level=0)
print('\nPayload sample:',data.head(5),sep='\n')
print('\n',data.dtypes)
data = data[['id','name','tagline','first_brewed','description','image_url','abv','ibu','target_fg',
'target_og','ebc','srm','ph','attenuation_level','volume']]
return data
# this defines the columns and data types going back out to Prep
def get_output_schema():
return pd.DataFrame({
'id' : prep_decimal(),
'name' : prep_string(),
'tagline' : prep_string(),
'first_brewed' : prep_string(),
'description' : prep_string(),
'image_url' : prep_string(),
'abv' : prep_decimal(),
'ibu' : prep_decimal(),
'target_fg' : prep_decimal(),
'target_og' : prep_decimal(),
'ebc' : prep_decimal(),
'srm' : prep_decimal(),
'ph' : prep_decimal(),
'attenuation_level' : prep_decimal()
})
In goes the dummy file (one column with one row) and the script step: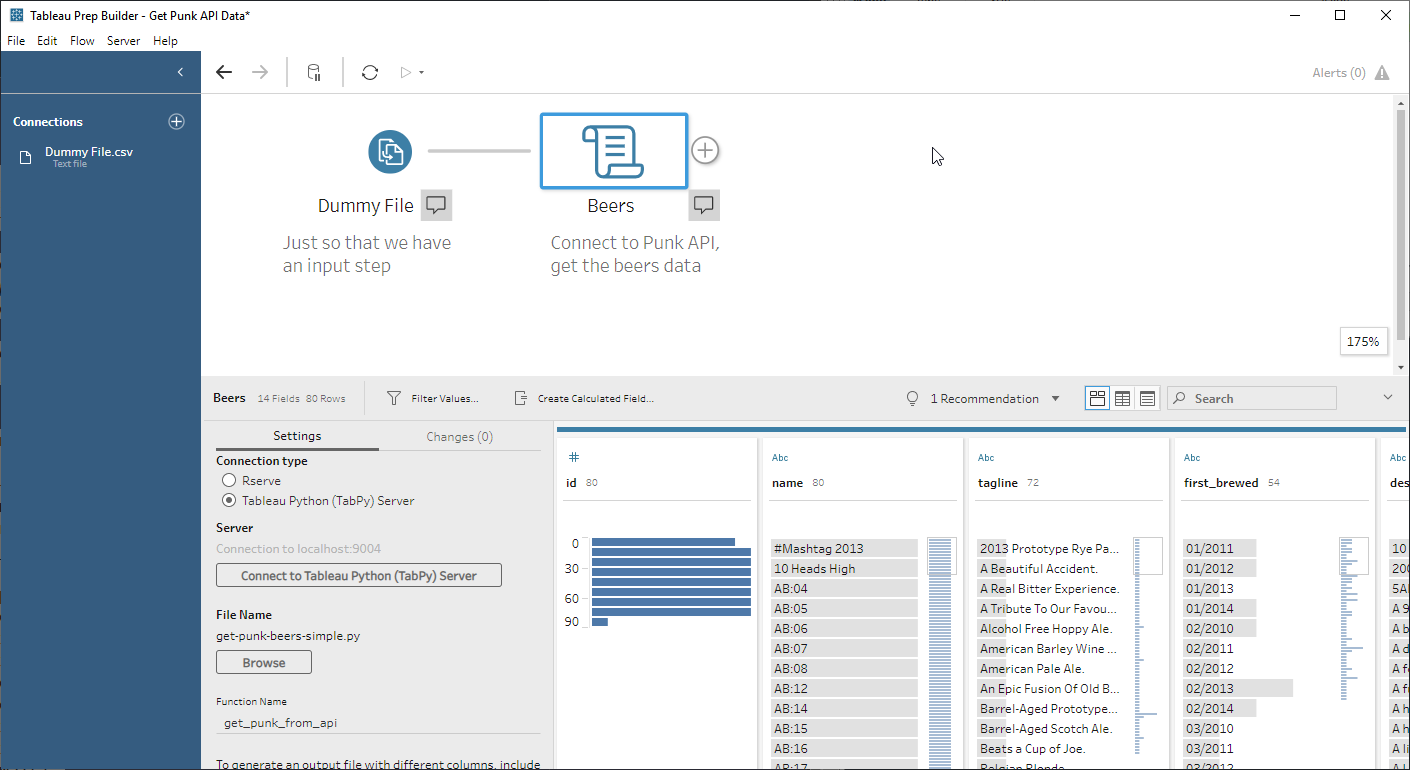
The end-to-end flow: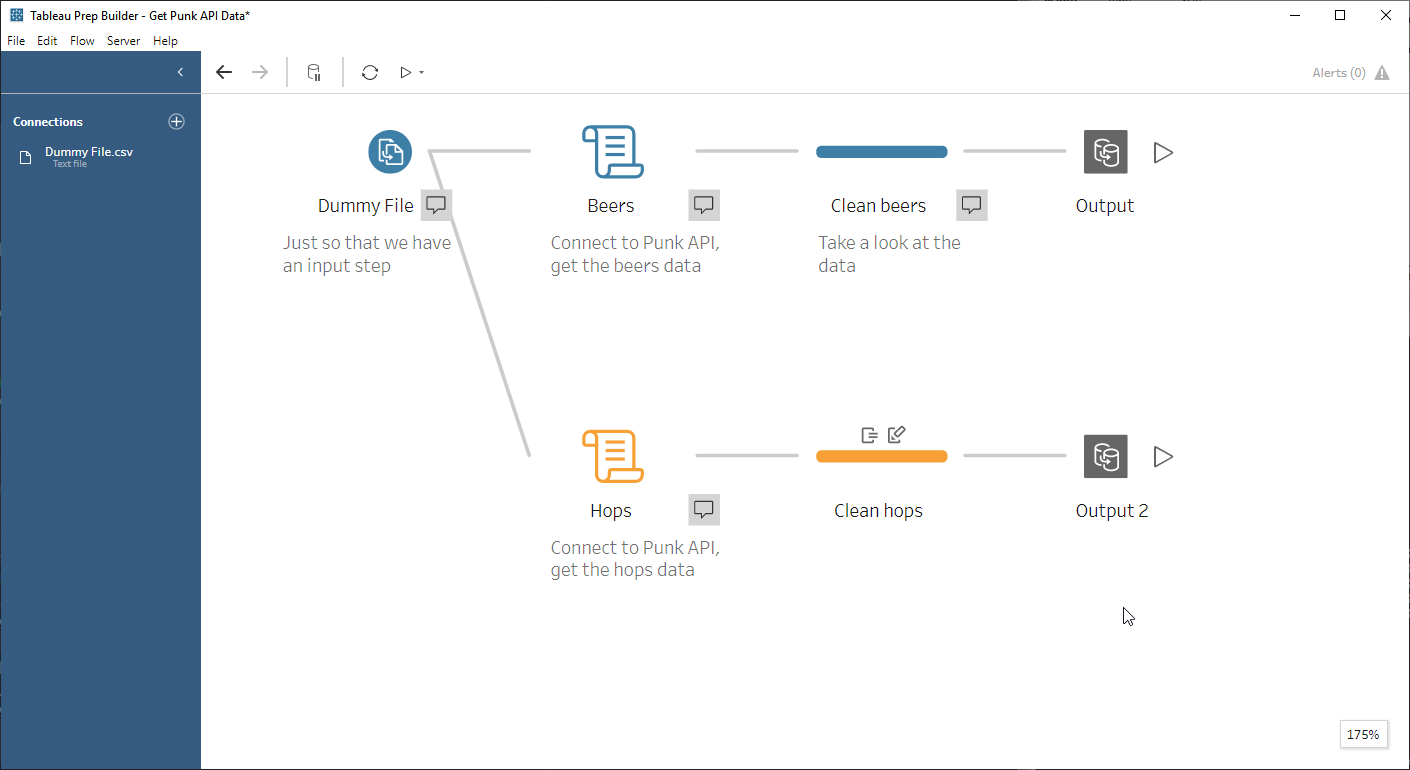
What next?
These have been very simple examples, and one thing that’s missing is any kind of parameterisation. In our deduping example we have to keep only the columns that we want to flag as duplicated; if we wanted our Is Duplicate column against our full dataset we’d have to aggregate down to one record per Order Id and Product Id, then join back to the original table. Ideally we’d like to be able to tell our simple_dupe_detect function which columns to check across without having to hard code it in – and I’ll cover my solution for this in a follow-up blog post.
Download the files for this post here.